Bonjour à toute la communauté Finary,
Je suis investisseur passionné, ingénieur de formation. Je travaille dans le domaine du private equity depuis plusieurs années et j’ai environ 30 ans. Pour mon besoin personnel, et parce que j’aime le challenge que je peux difficilement combler dans mon travail, j’ai développé un outil qui pourrait intéresser certains d’entre vous.
J’ai conçu des modèles d’IA dont l’objectif est de réaliser une réallocation d’un portefeuille d’actif à temporalité constante (journalier, hourly, etc). L’objectif simple était de répondre à ce besoin personnel : optimiser mes investissements sans y consacrer des heures chaque jour, et surperformer les indices de base devenus références.
Après plusieurs années d’exploration scientifique, j’ai enfin réussi à obtenir des modèles « viables »; le faible coût des GPUs m’a aidé. Cela m’a permis, sans rentrer dans les détails techniques, de pouvoir sélectionner des modèles et comparer très rapidement à un index ou une stratégie buy & hold simple. J’ai pu aussi créer différentes typologies de modèle (avec plus ou moins de risque globalement).
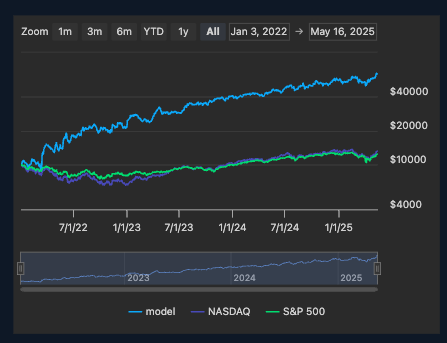
Je dis viable parce que sur des périodes de backtests longues (sur des périodes non utilisées pour l’apprentissage), je surperforme les indices (S&P 500, Nasdaq, MSCI W.) assez largement.
Par exemple j’utilise la plage du 01/01/2022 à aujourd’hui (16/05/2025) pour mes backtests. Sur cette plage, avec un seul investissement en début de période j’observe :
- Entre 20 et 50% de CAGR
- Une volatilité supérieure mais maîtrisée (entre 5 et 25% supérieure aux indices)
- Un sharpe ratio supérieur à 1 systématiquement
- Max drawdown vs indice : maîtrisé, parfois supérieur à l’index, parfois inférieur
Encore une fois, je ne vais pas rentrer dans les détails techniques, mais j’élimine les modèles sous ces seuils.
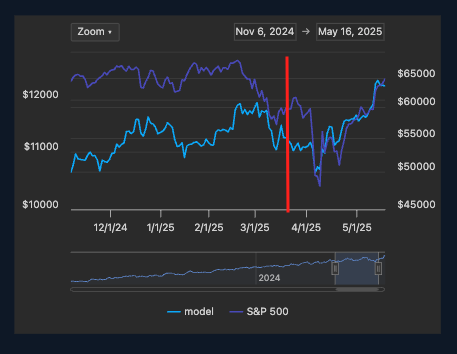
Par exemple, voici les perfs d’un de mes meilleurs modèles sur cette période de backtesting de 2022 à date (avec un overview de la composition du portefeuille sélectionné initialement + les allocations arbitrées par l’IA (c’est un peu fouillu mais ça donne un overview)) :

(pour rappel, le backtest tourne sur des données de validation, que le modèle n’a jamais vu pendant l’apprentissage)
J’ai (et je) consacré beaucoup de soir et weekend à ce projet, quand quelque chose passionne ça aide.
J’ai donc continué cette aventure; depuis début d’année j’ai (1) trouvé des brokers disponibles via API à 100% (avec 0% de frais car je fais de la réallocation périodique), (2) industrialisé l’usage de mes modèles en créant une API pour les utiliser, (3) créé une petite plateforme permettant de consulter les modèles et obtenir des métriques quants visuellement (4), et finalement connecté tout bout-à-bout : lancer des bots utilisants les modèles et réalisant les arbitrages pour moi tous les jours.
L’objectif principal étant de vérifier qu’en condition réelle (achat/vente sur le marché, différence de prix entre inférence et rebalancing, etc etc etc), j’obtiens bien un résultat quasi-équivalent au backtest. Je vous confirme, c’est bien le cas.
Je suis donc dans une situation où je peux me dire que j’utilise mes modèles pour moi et ça va comme ça, ou qu’en réalité ils ont bien plus de valeur si ils sont utilisés par d’autre.
Je cherche des retours sur la suite à donner à mon projet :
- Est-ce que ce type d’approche vous intéresse pour une partie de votre portefeuille ?
- Quelles métriques ou fonctionnalités seraient indispensables selon vous ? Et quels pourraient être les freins à l’utilisation ?
- Quel business modèle si je décide de ne pas garder ça pour moi et surtout à quel coût ? (oui je parle de coût avant même d’entrée financière car par exemple même si je voulais donner l’usage de mes modèles à un ami, d’après ma compréhension simplifiée il faudrait passer par la case AMF et débourser plusieurs dizaines de k€ « juste pour ça »)
Merci d’avance pour votre lecture, et peut-être vos retours ![]()